Optimizing MAX Phases with Featurization
![]()
Some design spaces cannot be reduced to simple, continuous representations that can be fed into Ax. For example, material compositions often span the periodic table and are subject to non-linear constraints like parsimony and electron counting rules that would be impossible to express in an Ax parameters object. One possible solution is to represent the composition as a one dimensional vector of the molar fractions of the materials’ constituent elements. However, this representation assumes simple elemental substitution rules, which tyically only hold in limited composition ranges. Additionally, such a representation provides the model with little information about the unerlying physics and has been shown to be a weak predictor of material properties.
Featurization is the process of creating new representations that better describe the input data and are more ammendable to statistical modeling. In the context of material compositions, featurization typically involves creating a weighted combination of teh constituent elements’ atomic properties. In this scheme, a material like Al2O3 is represented as a vector by averaging the properties of aluminum and oxygen, weighted by their molar fractions. In this tutorial, the popular featurization package,CBFV, will be used to perform the featurization task.
MAX phase materials are a specialized group of compounds that blend the properties of metals and ceramics. MAX phase compositions are comprised of M, a transition metal; A, a group 13 or 14 element; and X, carbon or nitrogen. MAX phases are of particular interest in high temperature, structural applications.
You have been tasked with finding a new MAX phase composition with a high elastic modulus to be used as a cladding material in a next generation nuclear reactor. A colleague in your lab spent a few weeks looking through the literature and has identified a set of reported MAX phase materials that haven’t been tested for modulus, but look promising.
You believe Bayesian optimization can help faciliate this search, and decide to use Honegumi to help construct an optimization script.
To simulate this task, a helper function is provided that automatically pulls and splits the data in a representative way. An explanation of this function is provided in subsequent cells and in line comments. Although optimal values could easily be found using the tabulated data, we will pretend that such data is unknown and use Bayesian optimization to find the optimal material instead.
[8]:
import matplotlib.pyplot as plt
from CBFV import composition
from matminer.datasets import load_dataset
def generate_data(seed=42):
"""
Constructs training and cadidate data from a benchmark MAX phase dataset by sampling
8 points with elastic modulus <= 200 GPa for training and using the remaining data
as candidates for optimization.
Args:
seed (int): Random seed for reproducibility. Default is 42.
Returns:
tuple: A tuple containing two DataFrames:
- `train`: A DataFrame of 8 sampled points with elastic modulus <= 200 GPa.
- `candidate`: A DataFrame of the remaining data after sampling.
"""
# load benchmark dataset, pull the formula and elastic modulus
data = load_dataset("m2ax", pbar=True)[['formula', 'elastic modulus']]
data.rename(columns={'elastic modulus': 'target'}, inplace=True)
# generate an initial data by sampling 8 points with elastic modulus <= 200 GPa
train = data[data.target <= 200].sample(n=8, random_state=seed)
candidates = data.drop(train.index)
return train, candidates
Featurizing Compositions
In the code cell below, we will featurize the training and candidate materials using the CBFV packages. In the interest of keeping the tutorial simple, we will subsample the generated features, keeping every 20th feature.
[9]:
# create training and candidate datasets
train, candidates = generate_data()
# show the first five compositions in the training set
display(train.head())
# featurize the compositions, keep every 20th feature for tutorial simplicity
X_train, y_train, formula, _ = composition.generate_features(train)
X_train = X_train.iloc[:, ::20]
X_candidates, y_candidates, _, _ = composition.generate_features(candidates)
X_candidates = X_candidates.iloc[:, ::20]
Reading file /Users/andrewf/miniconda3/envs/ax_env_pip/lib/python3.10/site-packages/matminer/datasets/m2ax.json.gz: 0it [00:00, ?it/s]0, ?it/s]
Decoding objects from /Users/andrewf/miniconda3/envs/ax_env_pip/lib/python3.10/site-packages/matminer/datasets/m2ax.json.gz: 0it [00:00, ?it/s]
| formula | target | |
|---|---|---|
| 89 | Cr2SnN | 141 |
| 45 | Ti2TlN | 200 |
| 111 | Mo2PbN | 138 |
| 174 | Hf2CdC | 174 |
| 0 | Sc2AlC | 140 |
Processing Input Data: 100%|██████████| 8/8 [00:00<00:00, 30504.03it/s]
Featurizing Compositions...
Assigning Features...: 100%|██████████| 8/8 [00:00<00:00, 10443.33it/s]
Creating Pandas Objects...
Processing Input Data: 100%|██████████| 215/215 [00:00<00:00, 51957.56it/s]
Featurizing Compositions...
Assigning Features...: 100%|██████████| 215/215 [00:00<00:00, 19595.29it/s]
Creating Pandas Objects...
Applying Honegumi
We will now use the Honegumi website to generate a script that will help us optimize our material composition for elastic modulus. Unlike other tutorials, however, this will require more extensive modifications to the generated script in order to facilitate feeding in predefined candidate solutions. From the description, we observe that our problem is a single objective optimization problem with some existing materials data. Additionally, as our problem doesn’t have a simple continuous representation, typical Sobol generation won’t work, so we will want to adjust the generation strategy somewhat, which can be exposed by selecting the Fully Bayesian option.

The Honegumi generated optimization script will provide a framework for our optimization campaign that we can modify to suit our specific problem needs. In the code sections below, we will make several modifications to this generated script to make it compatible with our problem.
Modifying the Code for Our Problem
We can modify this code to suit our problem with a few simple modifications. Wherever a modification has been made to the code, a comment starting with # MOD: has been added along with a brief description of the change.
[ ]:
import numpy as np
import pandas as pd
from ax.service.ax_client import AxClient, ObjectiveProperties
import matplotlib.pyplot as plt
from ax.modelbridge.factory import Models
from ax.modelbridge.generation_strategy import GenerationStep, GenerationStrategy
from botorch.acquisition import UpperConfidenceBound
obj1_name = "elastic_modulus" # MOD: change objective name
# MOD: remove the branin dummy objective function, we will use tabulated data
# MOD: remove dummy training data, we defined this in an earlier cell
n_train = len(X_train)
gs = GenerationStrategy(
steps=[
# MOD: remove sobol sampling step
GenerationStep(
model=Models.BOTORCH_MODULAR,
num_trials=-1,
max_parallelism=3,
model_kwargs={}, # MOD: no model kwargs
),
]
)
ax_client = AxClient(generation_strategy=gs,
random_seed=42) # MOD: add random seed for reproducibility
ax_client.create_experiment(
parameters=[ # MOD: create flexible parameters for all generated features
{"name": feat, "type": "range", "bounds": [-1e5, 1e5]}
for feat in X_train.columns
],
objectives={
obj1_name: ObjectiveProperties(minimize=False) # MOD: set minimize = FALSE
},
)
# Add existing data to the AxClient
for i in range(n_train):
parameterization = X_train.iloc[i].to_dict()
ax_client.attach_trial(parameterization)
ax_client.complete_trial(trial_index=i, raw_data=y_train.iloc[i]) # MOD: use iloc
from ax.core.observation import ObservationFeatures # MOD: import ObservationFeatures
selected_indices = [] # MOD: create list to store selected indices
for i in range(n_train, n_train + 19): # MOD: account for training data in trial num
ax_client.fit_model() # MOD: fit the model to the known data
model = ax_client.generation_strategy.model # MOD: get model object as var
# MOD: define candidates as ObservationFeatures before passing to model
obs_feat = [
ObservationFeatures(
{col: val for col, val in zip(X_candidates.columns, X_candidates.iloc[i])}
)
for i in range(len(X_candidates))
]
# MOD: evaluate the acquisition function on each candidate, and pull the best
acqf_values = np.array(
model.evaluate_acquisition_function(observation_features=obs_feat)
)
acqf_values[selected_indices] = -100 # give prev selected points a low value
best_index = np.argmax(acqf_values) # get the index of the best candidate
selected_indices.append(best_index) # append this to the selected indices list
results = y_candidates.iloc[best_index] # MOD: "measure" the best idx candidate
ax_client.attach_trial(X_candidates.iloc[best_index].to_dict())
ax_client.complete_trial(trial_index=i, raw_data=results)
[NOTE] The output of the above cell has been hidden in the interest of clarity.
[11]:
# Plot results
objectives = ax_client.objective_names
df = ax_client.get_trials_data_frame()
fig, ax = plt.subplots(figsize=(6, 4), dpi=150)
ax.scatter(df.index, df[objectives], ec="k", fc="none", label="Observed")
ax.plot(
df.index,
np.maximum.accumulate(df[objectives]), # MOD: change to maximum
color="#0033FF",
lw=2,
label="Best to Trial",
)
ax.axvline(n_train+0.5, color="k", ls="--", lw=1) # MOD: mark end of training data
ax.set_xlabel("Trial Number")
ax.set_ylabel(objectives[0])
ax.legend()
plt.show()
[WARNING 01-28 12:56:31] ax.service.utils.report_utils: Column reason missing for all trials. Not appending column.
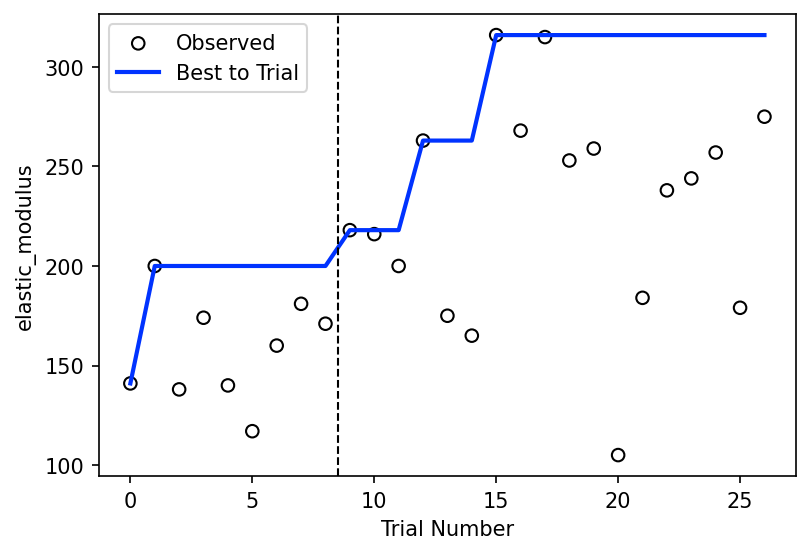
Show the Best Material
After our optimization loop has completed, we can look through the data to find the best discovered material.
[12]:
best_trial_index = ax_client.get_trials_data_frame()[obj1_name].idxmax()
print("\nBest Material: ", formula[selected_indices[best_trial_index]])
[WARNING 01-28 12:56:31] ax.service.utils.report_utils: Column reason missing for all trials. Not appending column.
Best Material: Cr2SnC
Next Steps
Interested in taking this further? Try to implement the following on your own!
It is often desireable to find many promising candidates. How long does it take for the model to find the top 5% of the dataset used in this tutorial?
Here we deliberately removed most of the generated features in the interest of simplicity and because GP models often scale poorly to high dimensions. One of the included model classes
Models.SAASBOis designed for such situations. Try running the script again using a SAASBO model and with a larger number of features.